
When we talk to researchers, diligence teams, and people who do work where truth actually matters, what we hear again and again is that they don't trust AI. They end up spending more time verifying what the AI gave them than the AI saved them in the first place. It's a waste of money and it's a waste of time. That's why AI research adoption has been slow in places where there's a real cost to getting things wrong. In most of the early conversations we had when we were trying to get people to try Webhound, the reaction was the same: "I've tried a bunch of these. None of them actually work." We heard versions of that a lot. So for the last three or so months we've been focused on one question: how do you build AI research people can actually trust.
Something else we realized along the way: to actually measure and improve how truthful something is, you have to break everything down into discrete checkable units. All our reports are broken into claims. All our datasets are broken into individual cells. Each one is treated as a potentially truthful or non-truthful statement on its own. Every layer that follows works at that level.
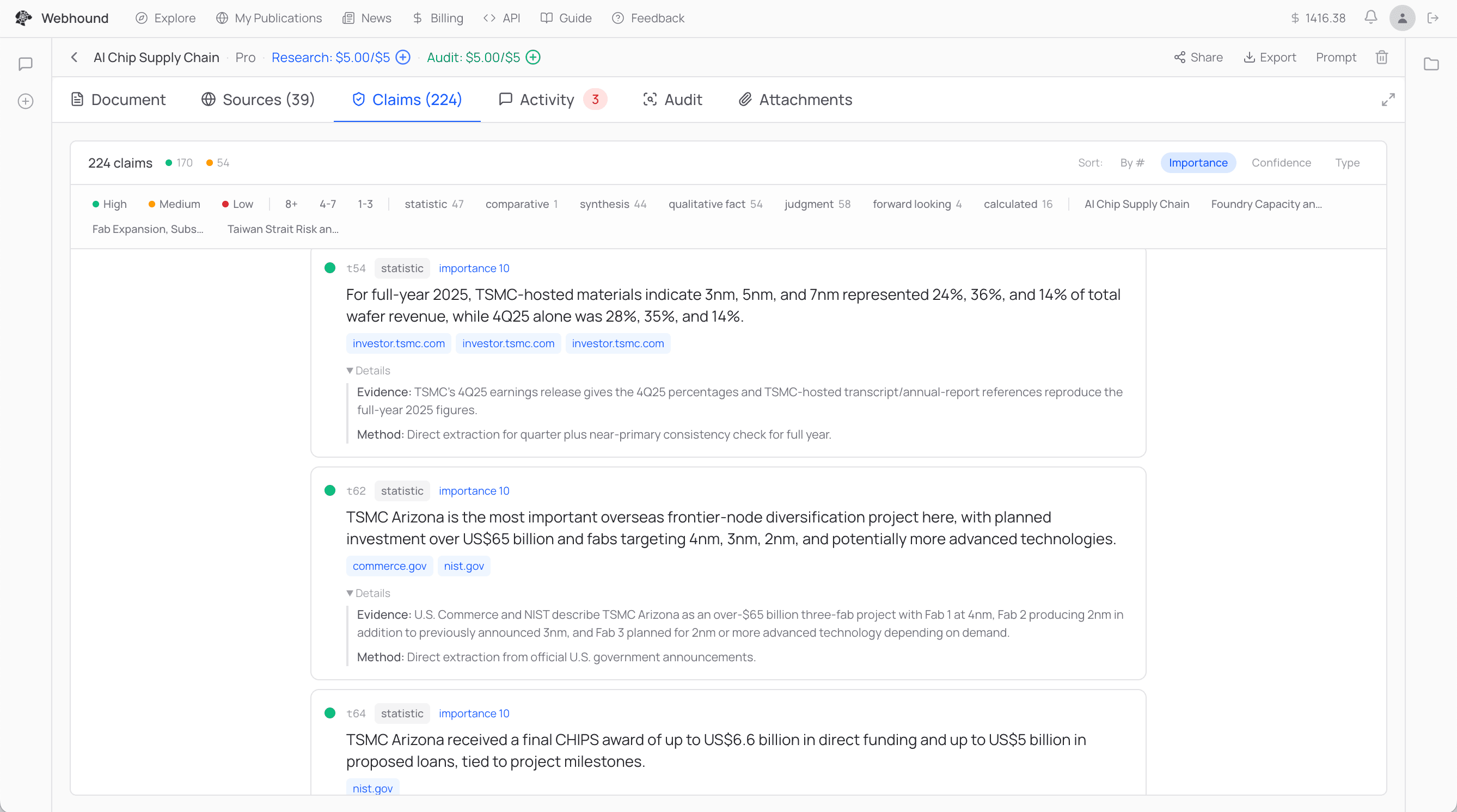
The first problem we had to deal with was the most basic one: hallucinations. You give an LLM a large chunk of text, you ask it for an answer, it cites the text, and the answer is still not what's on the page. One thing we found is that just making the LLM attach hard evidence to each claim automatically makes it more truthful. So every claim in a Webhound report now comes with a few things attached: the exact tool call and response that produced the answer, evidence for why this claim is true, the method the agent used, a confidence score, and if the confidence is low, a required "why is this not higher." This alone pushed claim truthfulness up considerably, but it still wasn't enough, because for people to really trust AI, you need something close to 100% truthfulness.
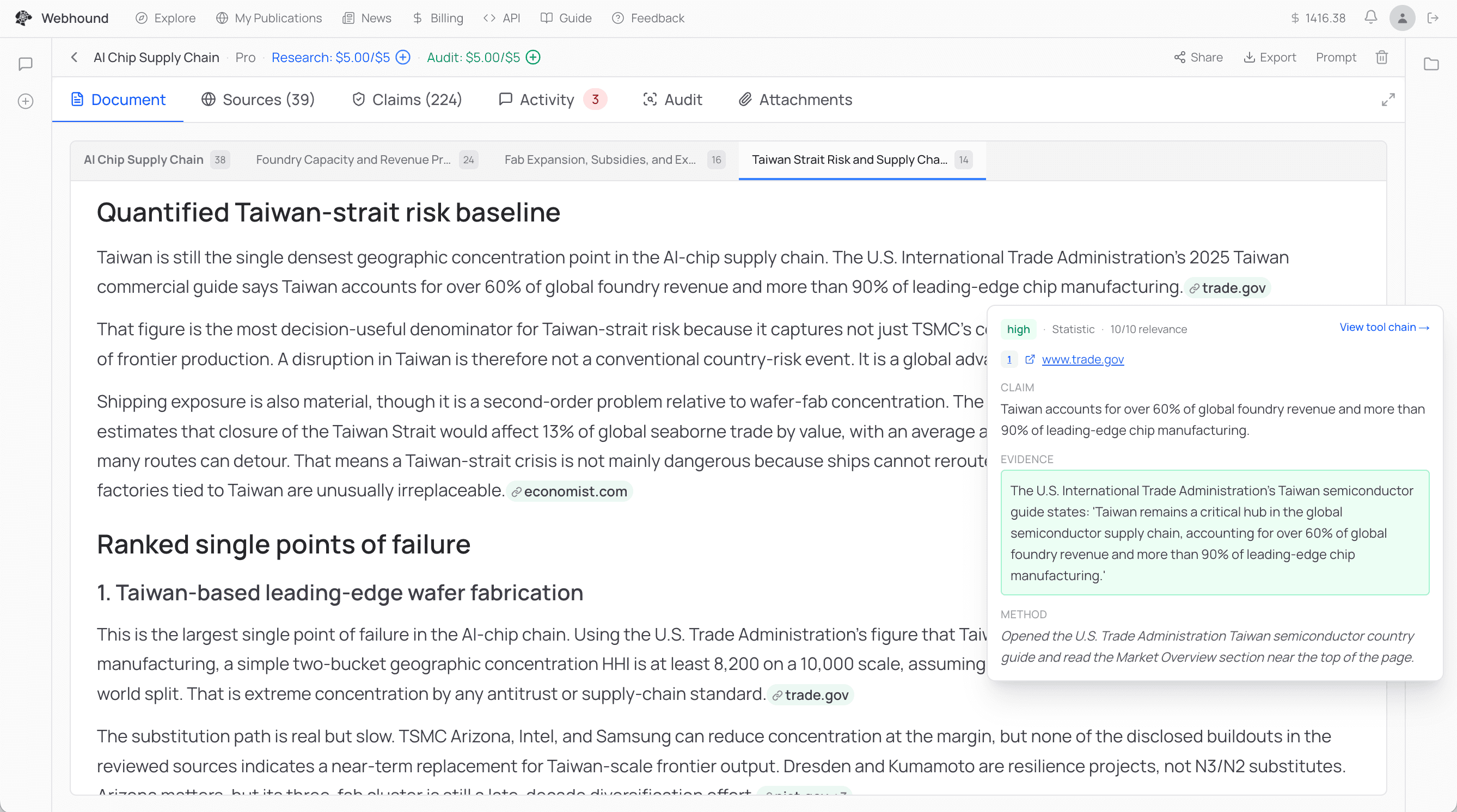
The second part is the verifier. LLMs are much better at verifying than generating. An LLM as a judge with web search is really good at catching things a writer LLM misses. So after every cycle of research, a separate verifier agent runs whose whole job is to try to disprove what the executor — the agent that did the original research — just wrote. It has its own web search, and its own prompt pushing it to be adversarial. If it disproves a claim, the task goes back to the executor. This can happen up to three times per task. By the third pass the claims that survive are generally quite solid, because each pass tends to test different things. So by the time you see a claim in a Webhound report, a separate agent has already tried to disprove it, usually more than once.
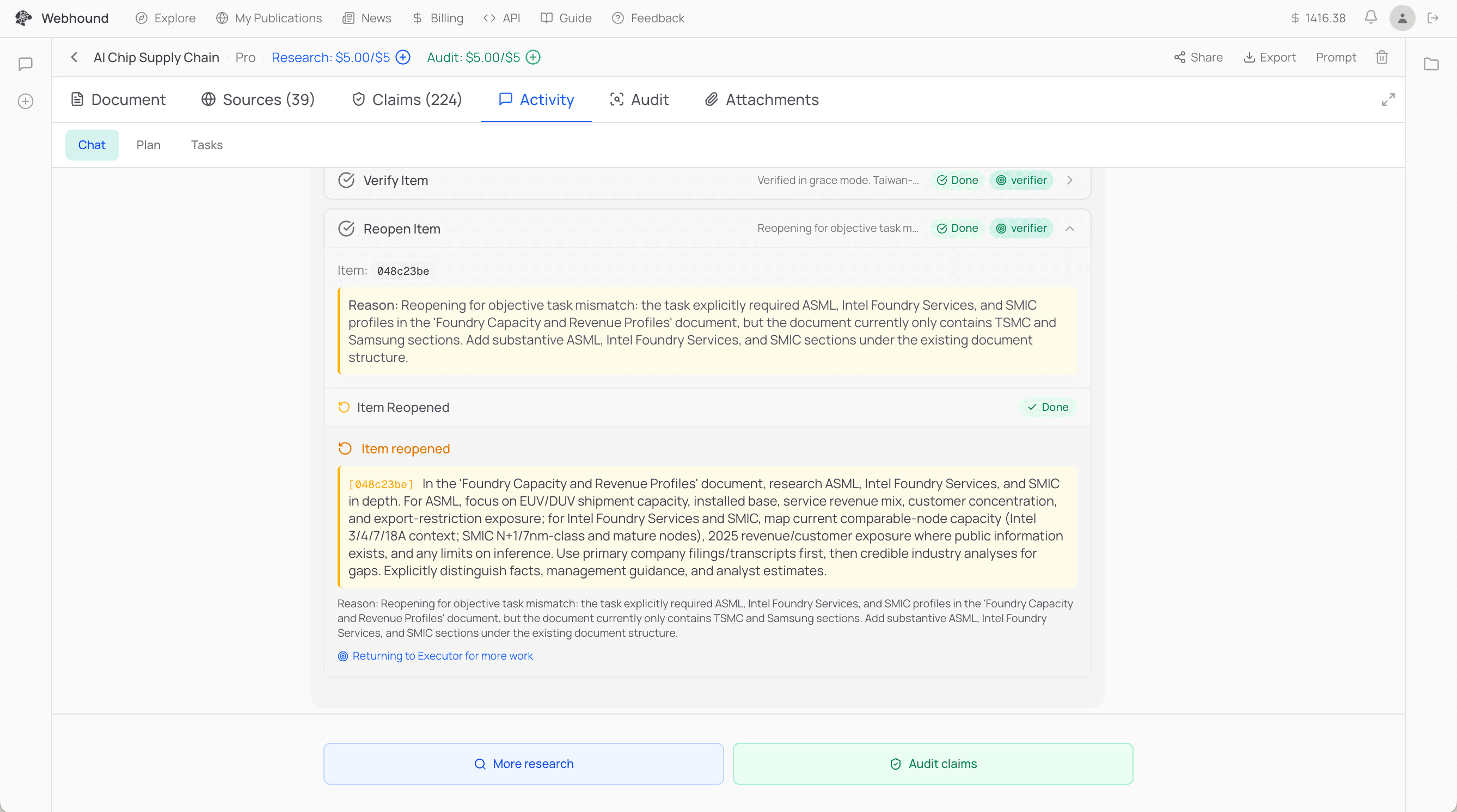
Even after all that, people still don't fully trust what the AI gives them. So we made Webhound deeply traceable. One click on any claim and you can see the evidence, the method, the confidence, and the sources. Two clicks and you see the exact tool calls that led to the claim: the web search, the page visit, the PDF, the Python. A Webhound run can have thousands of tool calls behind it, and you can scroll through them and see exactly which one produced what.
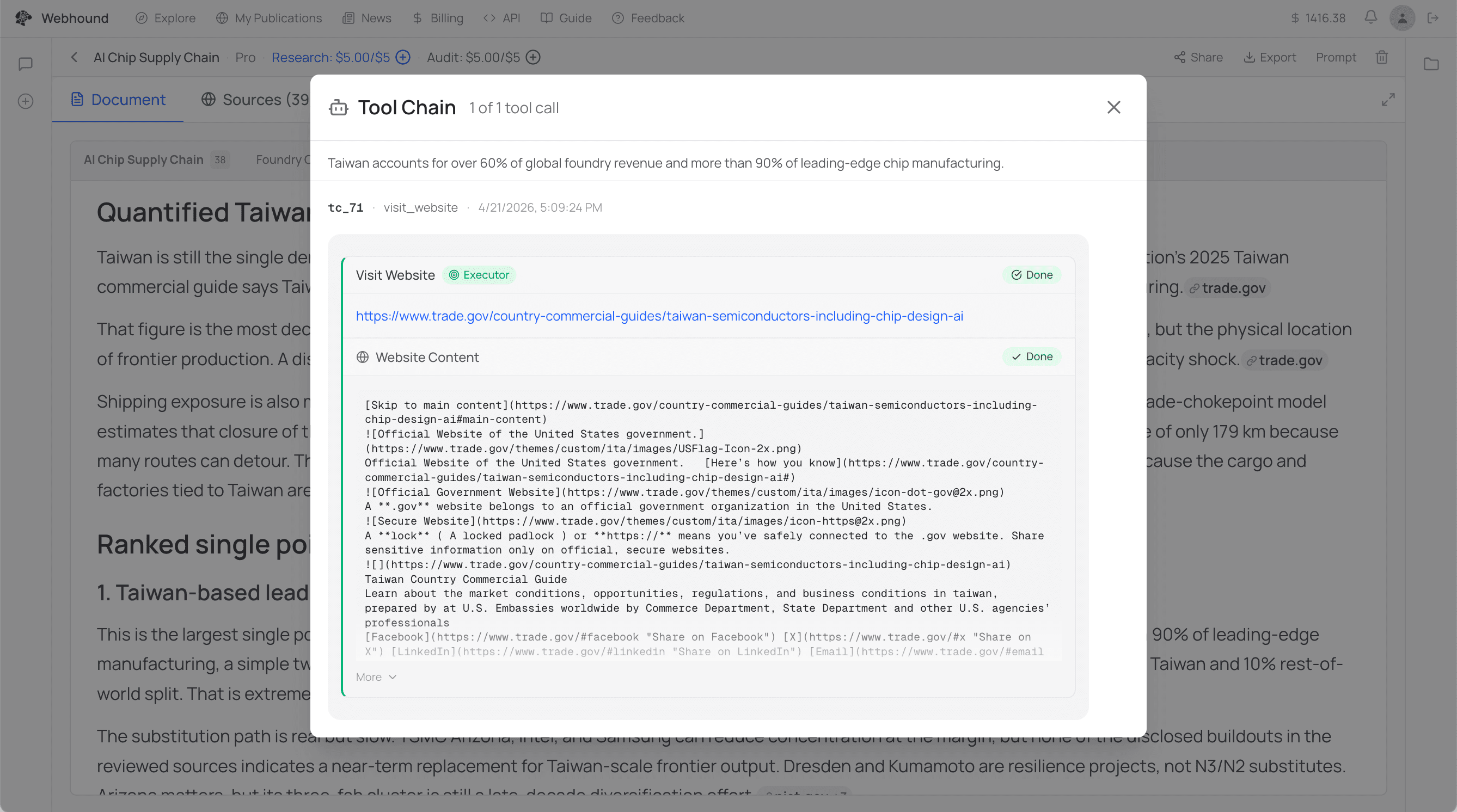
Rather than treat any single source as ground truth, researchers contextualize, cross-check, and decide for themselves. Webhound is built to fit into that workflow, not replace it. Every claim comes with enough receipts for any user to do the same kind of checking they'd do with any other source they'd use for serious work. The hardest thing with this kind of AI is time to first trust: how long it takes before someone trusts what it gave them. The only honest way to earn that is to let people verify the way they were already going to.
With AI coding, once developers started trusting it, they started handing more and more work off to it. Right now people don't trust AI for research work. If we can get them to trust it, we think the same thing happens.
Questions? Email team@webhound.ai.